Understanding Optical Character Recognition (OCR) Models
Optical Character Recognition (OCR) technology enables computers to recognize and interpret text from images or scanned documents. This innovative technology has transformed numerous applications, enabling efficient data extraction and digitization of printed materials. In this blog post, we will explore the core concepts of OCR models, their significance, and highlight some of the leading open-source OCR solutions available today.
What is Optical Character Recognition (OCR)?
Optical Character Recognition is a process that converts different types of documents, such as scanned paper documents, PDFs, or images captured by a digital camera, into editable and searchable data. The technology uses advanced algorithms and machine learning techniques to analyze and identify characters, making it a vital tool in various industries.
How OCR Works
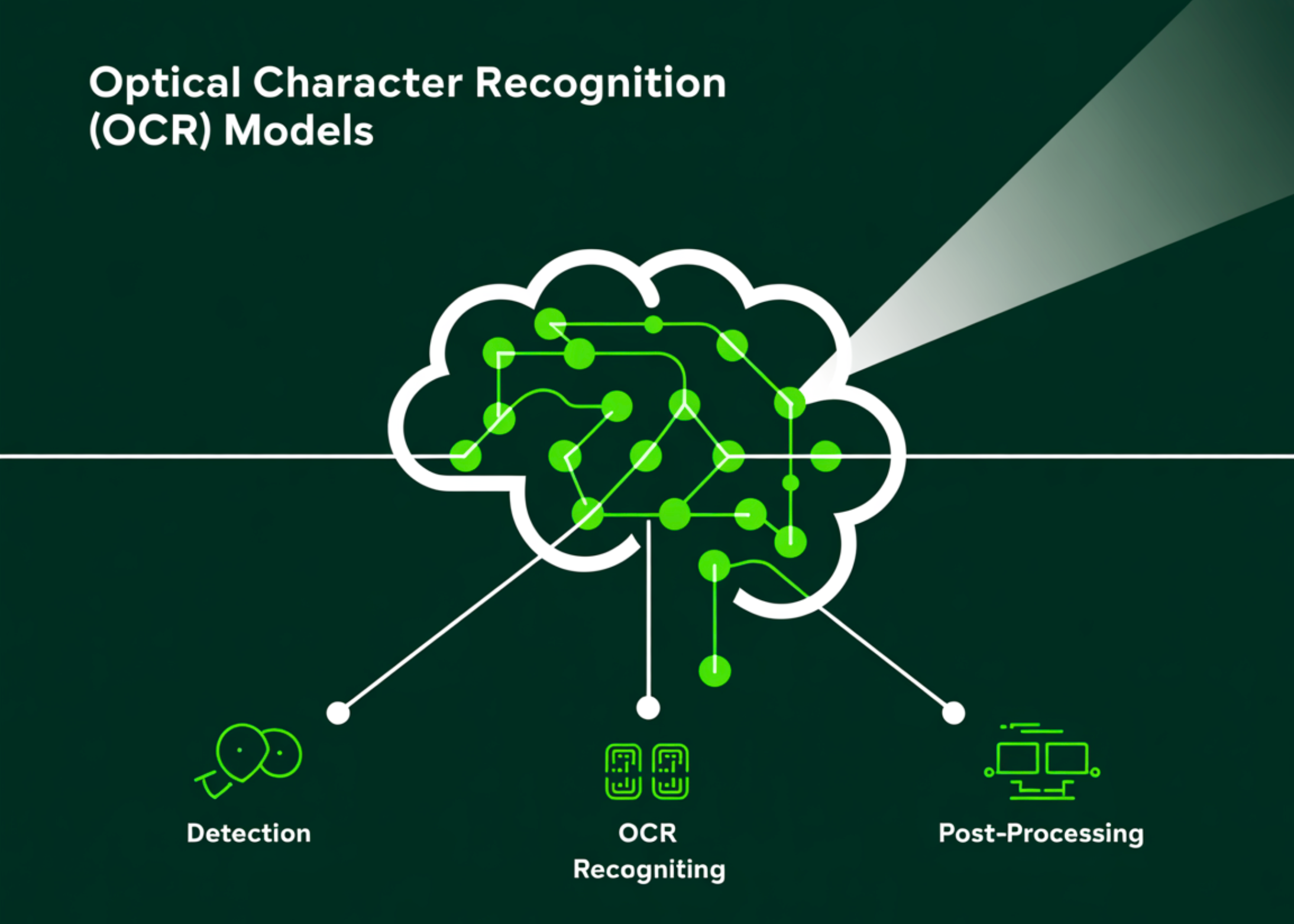
The OCR process can be broken down into several distinct steps:
-
Image Preprocessing: This initial step enhances the quality of the input image, making it easier for the OCR model to recognize text. Techniques like noise reduction, binarization, and skew correction are commonly employed.
-
Text Detection: In this phase, the model identifies regions within the image where text exists. Various methods, including contour detection and connected component analysis, are used.
-
Character Recognition: Here, the actual recognition of characters occurs. The OCR model analyzes the identified text regions and translates them into machine-readable characters using classification algorithms.
- Post-Processing: Once the characters are recognized, the output may require further refinement. This can include error correction using dictionaries or language models to improve accuracy.
Importance of OCR Technology
The significance of OCR technology cannot be overstated. It facilitates:
-
Automation: Businesses can automate data entry tasks, reducing human errors and increasing productivity.
-
Accessibility: OCR enhances accessibility for individuals with visual impairments by converting printed material into formats that can be read by screen readers.
- Archiving and Documentation: OCR allows organizations to digitize and archive historical documents, making them easier to store and search.
Top Open-Source OCR Models
Several open-source OCR models have gained popularity due to their robust features and community support. Here are some of the most notable options:
1. Tesseract
Tesseract is perhaps the most well-known open-source OCR engine. Developed by Google, it supports over 100 languages and is highly customizable. Key features include:
- Multi-language Support: Tesseract can recognize text in multiple languages, making it versatile for global applications.
- Extensibility: Developers can enhance Tesseract’s capabilities by training it on new fonts or handwriting styles.
- Integration: Tesseract can be easily integrated into various applications and platforms, including web and desktop environments.
2. EasyOCR
EasyOCR is a relatively new player in the OCR space, gaining attention for its ease of use and powerful features. Some highlights include:
- Deep Learning Based: EasyOCR leverages deep learning techniques to improve recognition accuracy, especially for complex texts.
- Multiple Language Support: It supports over 80 languages, catering to diverse user needs.
- User-Friendly API: EasyOCR’s API simplifies the integration process for developers, making it a popular choice for quick deployment.
3. OCRmyPDF
OCRmyPDF focuses on adding an OCR text layer to PDF files, making the documents searchable. Its main features include:
- PDF Compatibility: Designed specifically for PDF documents, allowing users to enhance existing PDFs without losing any quality.
- Batch Processing: OCRmyPDF can process multiple files simultaneously, making it efficient for large-scale projects.
- Easy Installation: It is straightforward to set up, allowing even non-technical users to utilize its features effectively.
4. PaddleOCR
Developed by PaddlePaddle, PaddleOCR is a powerful framework that emphasizes high performance and multilingual capabilities. Noteworthy attributes include:
- High Accuracy: PaddleOCR has been optimized for accuracy in recognizing various scripts and characters.
- Extensive Documentation: The model comes with comprehensive documentation, allowing users to quickly understand and implement it.
- Community Contributions: PaddleOCR benefits from an active community, providing ongoing support and feature enhancements.
5. Keras-OCR
Keras-OCR leverages the Keras deep learning framework and offers a robust solution for text detection and recognition. Key features include:
- Modular Design: Keras-OCR is built with a modular approach, enabling developers to customize various components according to their requirements.
- Real-time Processing: The framework is designed to handle real-time OCR tasks, making it suitable for applications in dynamic environments.
- Visualization Tools: Keras-OCR provides visualization tools for better understanding and debugging of text recognition tasks.
Considerations for Choosing an OCR Model
When selecting an OCR model, businesses and developers should consider several key factors:
-
Accuracy: The precision of text recognition is critical, especially for applications where error margins can lead to significant issues.
-
Performance: Evaluate how fast the OCR model processes images, particularly if high-volume document handling is required.
-
Language Support: Ensure that the model supports the languages relevant to your application, as this can impact usability significantly.
- Community and Support: Opt for models with active communities and good support channels, as this can be invaluable during implementation.
Conclusion
Optical Character Recognition technology has revolutionized how we process and manage text from physical documents. Choosing the right OCR model is essential for maximizing efficiency and accuracy in any application. With a variety of open-source options such as Tesseract, EasyOCR, OCRmyPDF, PaddleOCR, and Keras-OCR, organizations have the tools they need to streamline their operations and innovate their document handling processes.
By understanding the fundamentals of OCR, its applications, and the leading models available, you can make informed decisions that enhance your workflows and boost productivity in today’s ever-evolving digital landscape.