
Blog
3 pandas Workflows That Slowed to a Crawl on Large Datasets—Until We Turned on GPUs
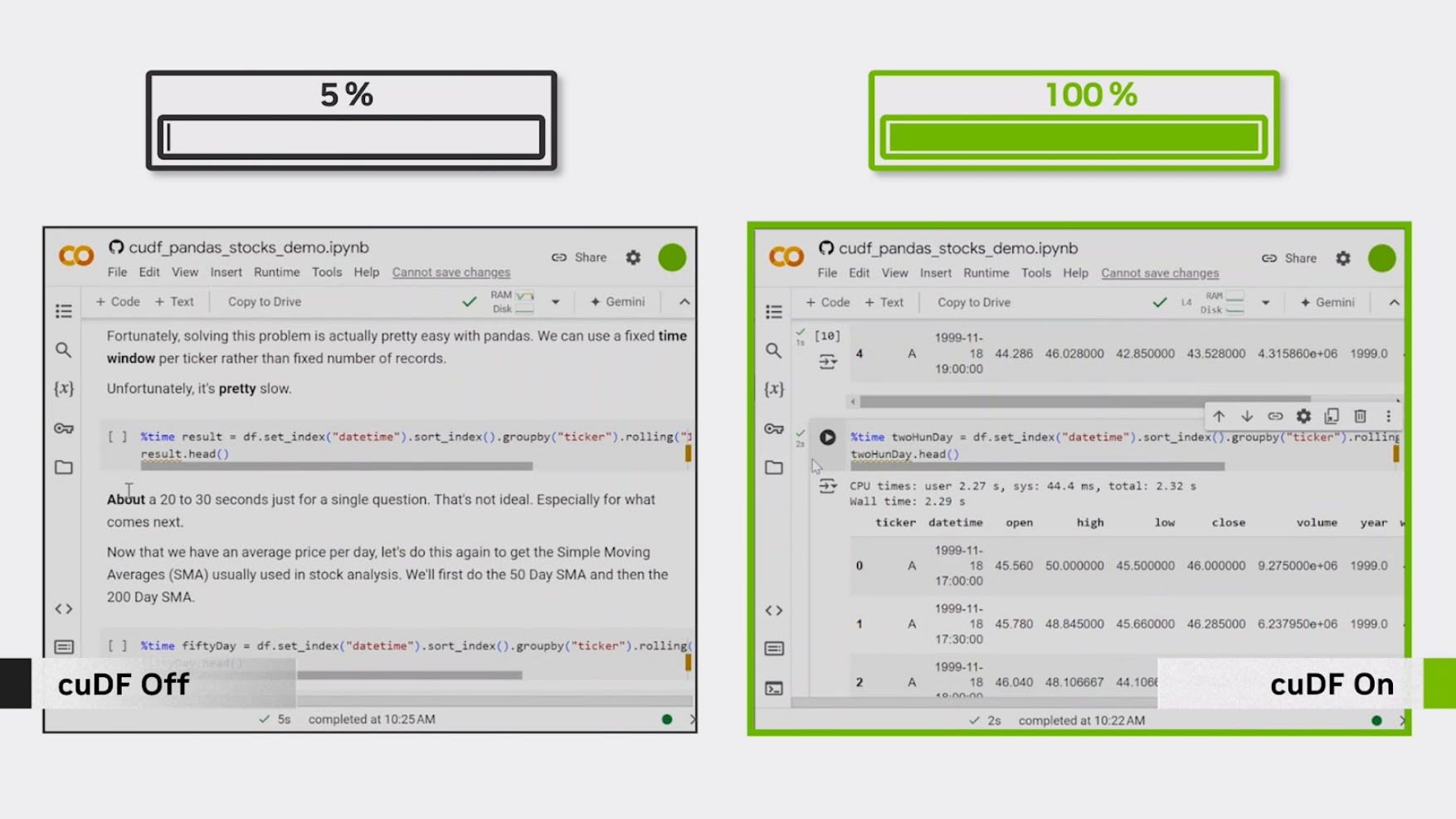
Introduction
As data analysts and developers increasingly rely on Python’s pandas library for data manipulation and analysis, many have experienced performance issues when working with large datasets. These challenges can lead to significant slowdowns in workflows, but there is a viable solution: leveraging GPU acceleration. In this blog post, we’ll explore three common pandas workflows that typically suffer from performance hits on large datasets and how enabling GPU capabilities can drastically improve execution speeds.
Understanding the Challenge with Large Datasets
When handling large datasets, the limitations of CPU processing become apparent. Operations that might seem straightforward on smaller sets can bog down, causing delays and frustrations for users. Typical issues include memory constraints, slow read times, and sluggish computation processes. Let’s delve deeper into three specific pandas workflows where these problems are prominent.
1. Data Loading and Preprocessing
The Problem
Loading and preprocessing data are foundational steps that set the stage for any analysis. However, when the datasets become vast—comprising millions of rows and numerous columns—operations like filtering, sorting, and merging can take significantly longer than anticipated. This increases wait times, which can disrupt the data analysis workflow.
The GPU Solution
Utilizing a GPU for these tasks can lead to impressive speedups. Libraries such as RAPIDS cuDF help in harnessing the GPU’s parallel processing capabilities, allowing for faster data loading and transformation. The parallel nature of GPUs can turn tasks that normally take minutes into ones that are executed in seconds.
Practical Example
Consider a dataset with several million entries, such as transaction records or sensor data. By using cuDF for loading this data into memory, analysts can experience a reduction in processing time, enabling quicker access and exploration of the data. This not only enhances productivity but also paves the way for immediate insights.
2. Data Analysis and Transformation
The Problem
Once data is loaded, the next step usually involves analyzing and transforming it to derive meaningful insights. Typical pandas operations, like groupby, pivot, and operations with complex aggregations, can become bottlenecks on large datasets. This is particularly true when dealing with operations that involve calculations across multiple columns.
The GPU Solution
Switching to a GPU-based library allows for these computations to be executed in parallel, significantly speeding up the analysis process. Tools within the RAPIDS ecosystem, such as cuDF and cuML, are tailored to accelerate data analysis tasks. They leverage GPU memory, making complex computations much more efficient.
Practical Example
For instance, when analyzing sales data to find annual trends, a typical groupby operation in pandas may take excessively long on a large dataset. However, with GPU acceleration, users can quickly compute metrics such as sums and averages across various segments, making real-time data-driven decisions more feasible.
3. Data Visualization
The Problem
Visualizing data is crucial for conveying insights effectively, but generating plots from large datasets can be performance-intensive. Constructing visualizations often requires aggregating and processing data before rendering, which can lead to long load times and unresponsive interfaces.
The GPU Solution
Using GPU-rendered visualizations can alleviate these issues significantly. Libraries like Datashader can generate visualizations from large datasets efficiently by handling data preprocessing on the GPU. This method bypasses the issues faced in standard plotting libraries that don’t leverage GPU capabilities.
Practical Example
Imagine attempting to visualize the distribution of millions of data points, such as customer transactions across geographical regions. Traditional visualization libraries may struggle to efficiently process this data, resulting in slow response times or even application crashes. By utilizing GPU-driven visualization tools, analysts can generate high-quality visualizations with enhanced interactivity, making data exploration a more seamless experience.
Implementation Tips for GPU Optimization
1. Choose the Right Libraries
Start by assessing your current workflow and identify which tasks are the most time-consuming. Integrate libraries that support GPU acceleration, such as RAPIDS cuDF and cuML for data manipulation and analysis, and Datashader for visualization.
2. Optimize Your Hardware Setup
Ensure that your system is equipped with a compatible GPU. Many tasks benefit from newer GPU architectures that offer improved performance. Pay attention to memory limitations as well, as large datasets require adequate GPU memory.
3. Familiarize Yourself with the Syntax
Transitioning to GPU-accelerated libraries often requires a shift in how code is written. Spend some time understanding the new syntax and methods provided by the GPU libraries to fully utilize their potential.
4. Test and Benchmark
Before fully committing to a GPU-accelerated workflow, run benchmarks on your typical tasks. Measure performance improvements against your standard pandas implementation to identify the instances where GPU acceleration offers substantial benefits.
Conclusion
Working with large datasets doesn’t have to hinder productivity. By identifying common bottlenecks in pandas workflows—data loading, analysis, and visualization—and implementing GPU acceleration, analysts can experience significant performance enhancements. Transitioning to a GPU-based ecosystem can streamline processes, making data manipulation and visualization faster and more efficient.
As the reliance on data continues to grow across various sectors, embracing these technologies is not just beneficial but essential for staying competitive in a data-driven landscape. By leveraging the power of GPUs, data professionals can navigate large datasets with ease, unlocking insights more rapidly than ever before.

