Introduction
The world of data science has seen exponential growth, and platforms like Kaggle have become vital for enthusiasts and professionals alike. Among the community, Kaggle Grandmasters stand out due to their remarkable achievements in competitive data modeling. In this post, we will explore seven proven modeling techniques that can elevate your tabular data processing skills to new heights. Whether you’re a beginner or an experienced data scientist, these strategies will enhance your ability to extract meaningful insights from your datasets.
Understanding Tabular Data
Before diving into modeling techniques, it’s essential to grasp what tabular data is. Tabular data is structured in rows and columns, much like a spreadsheet. Each row represents a record, while each column signifies a feature. This format is common in various applications, ranging from financial data to healthcare metrics. Understanding the structure is a foundational step toward effective modeling.
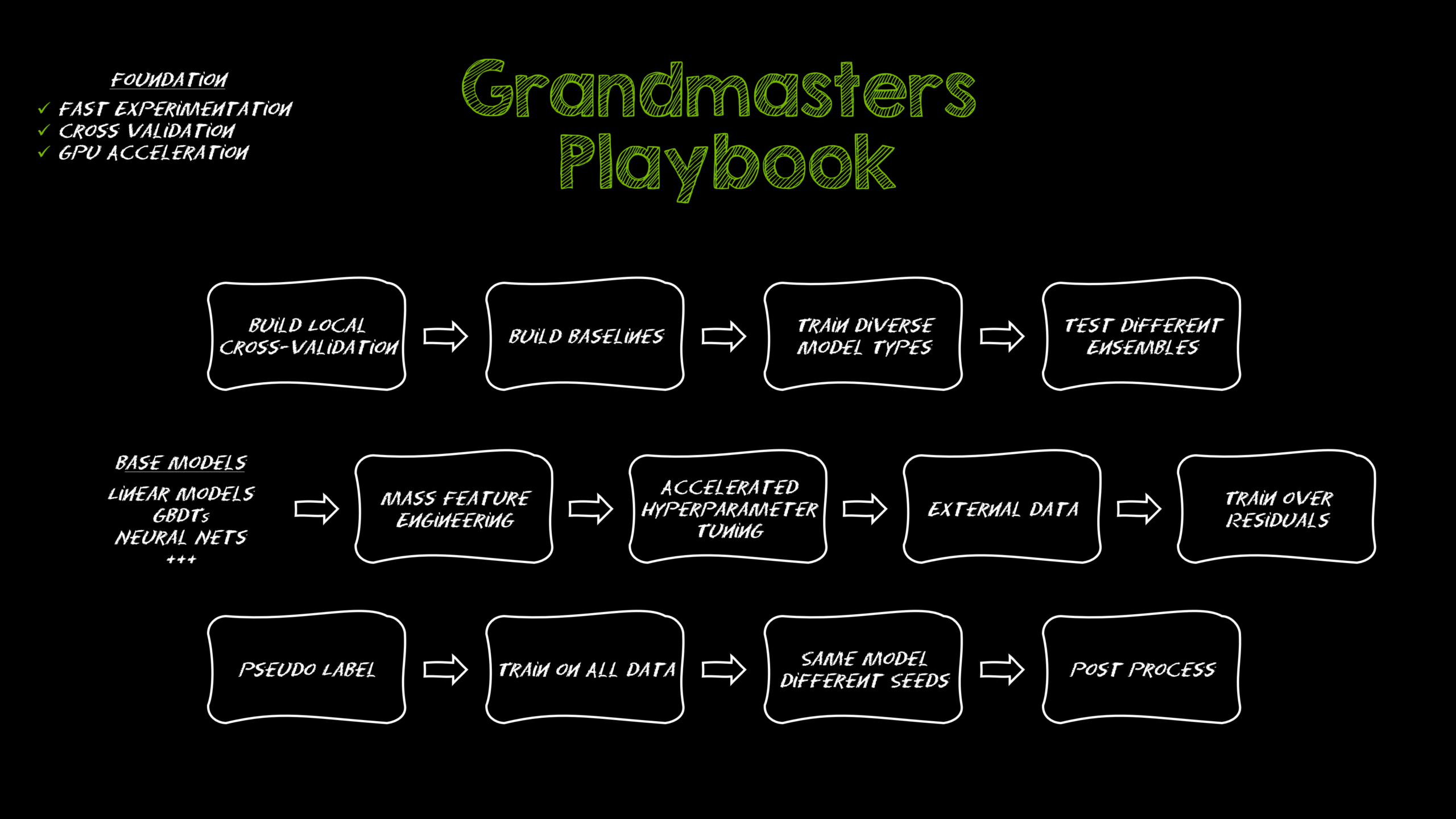
1. Feature Engineering: The Art of Creating Variables
Feature engineering involves selecting, modifying, or creating new variables to improve model predictive performance. It’s one of the most critical steps in any data science project. Techniques such as binning, normalization, and one-hot encoding can significantly impact your model’s accuracy.
Binning
Binning involves converting numerical variables into categorical ones. For example, instead of using age as a continuous variable, you can classify it into groups like "18-24," "25-34," etc. This transformation captures non-linear relationships and enhances model performance.
Normalization
Normalization scales numerical features to a standard range, often between 0 and 1. This step is essential when working with algorithms that are sensitive to the scale of data, such as neural networks.
2. Model Selection: The Right Tool for the Job
Choosing the right model is crucial for achieving optimal results. Each algorithm has its strengths and weaknesses, making it essential to align the model with the problem at hand.
Common Algorithms
- Linear Regression: Ideal for problems with a linear relationship.
- Decision Trees: Useful for capturing non-linear relationships while providing interpretability.
- Random Forests: An ensemble method that improves accuracy by averaging multiple decision trees.
- Gradient Boosting Machines (GBM): Effective for structured data, GBMs can enhance predictive performance by sequentially improving weak models.
Evaluating Models
Utilize techniques like cross-validation to assess model performance reliably. This practice helps ensure that your findings are robust and not overly biased by any particular subset of the data.
3. Hyperparameter Tuning: Optimizing Performance
After selecting a model, the next step is hyperparameter tuning. Hyperparameters are settings that dictate how your model learns from data. Fine-tuning these parameters can lead to significant performance gains.
Techniques for Tuning
- Grid Search: Explore a predefined set of hyperparameters to find the best combination.
- Random Search: A random selection of hyperparameters can often yield better results with less computational expense.
4. Handling Missing Values: Data Integrity Matters
Missing values are a common issue in tabular datasets. How you handle them can greatly influence your model’s performance. There are various techniques for addressing this challenge.
Imputation Methods
- Mean/Median Imputation: Filling missing values with the mean or median of the existing values.
- K-Nearest Neighbors (KNN): A more sophisticated technique where missing values are predicted based on similar records.
Deleting Missing Data
Sometimes, it may be beneficial to drop records or features with missing values if they constitute a small percentage of the dataset. However, ensure this doesn’t lead to loss of critical information.
5. Cross-Validation: Ensuring Robustness
Cross-validation is a powerful technique for verifying the stability and reliability of your model. It involves splitting your dataset into several parts, training the model on one subset, and validating it on another.
K-Fold Cross-Validation
In this method, the dataset is divided into ‘k’ subsets. The model trains on ‘k-1’ of these subsets and validates on the remaining one. This process is repeated ‘k’ times, allowing each subset to serve as a validation set once. This rigorous testing helps prevent overfitting.
6. Ensemble Methods: Combining Models for Better Predictions
Ensemble methods leverage the strengths of multiple models to enhance predictive accuracy. By combining different approaches, you can reduce bias and variance, leading to a more robust solution.
Bagging and Boosting
- Bagging: Short for Bootstrap Aggregating, this technique improves stability by training multiple versions of a model on different samples of the data and averaging their predictions.
- Boosting: This sequential technique focuses on correcting the errors made by the prior models, effectively improving overall performance.
7. Feature Importance: Understanding Your Data
Understanding which features significantly impact your model’s predictions is crucial. Various techniques can help assess feature importance, enabling you to focus on the most influential variables.
Techniques for Assessing Feature Importance
- Permutation Importance: Measures the effect of shuffling a feature on model performance.
- SHAP Values (SHapley Additive exPlanations): Provide insights into how features contribute to individual predictions, enabling better interpretability.
Conclusion
Mastering the art of data modeling, particularly for tabular data, requires a blend of skill, experience, and the right techniques. The seven strategies discussed here—feature engineering, model selection, hyperparameter tuning, handling missing values, cross-validation, ensemble methods, and understanding feature importance—serve as a comprehensive framework to enhance your modeling effectiveness. By implementing these battle-tested techniques, you can significantly improve your predictive analytics and gain deeper insights from your data.
Whether you’re participating in competitions on platforms like Kaggle or undertaking your projects, these strategies will empower you to navigate the complexities of data science with confidence.