
Blog
Memory-R1: How Reinforcement Learning Supercharges LLM Memory Agents
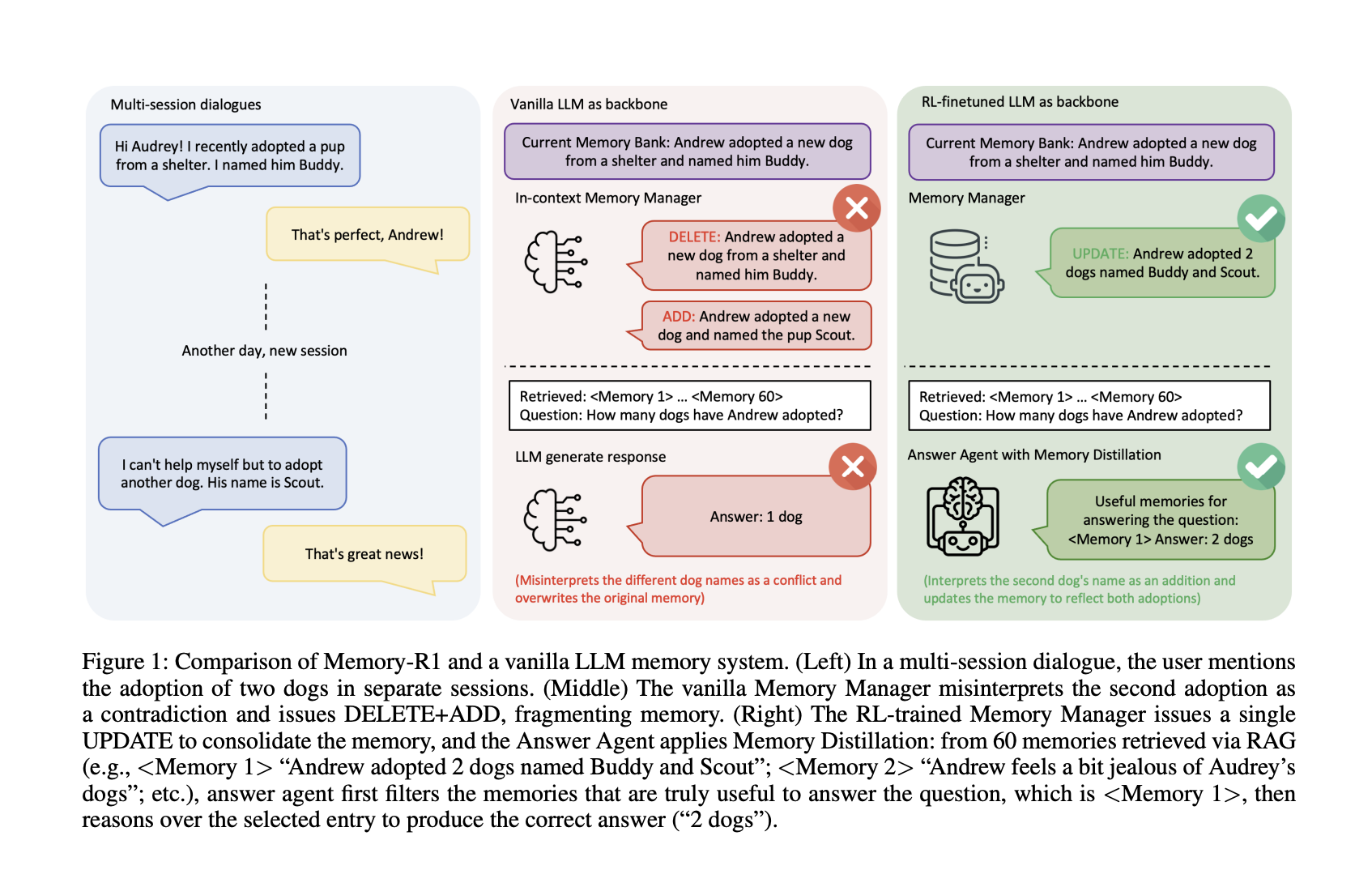
Understanding Memory-R1: The Impact of Reinforcement Learning on LLM Memory Agents
In the ever-evolving landscape of artificial intelligence, the integration of reinforcement learning with large language models (LLMs) is a game changer. This fusion, often referred to as Memory-R1, enhances the memory capabilities of LLMs, significantly improving their performance across various applications. In this post, we will explore how Memory-R1 operates, its advantages, and the future it holds in the realm of AI.
What is Memory-R1?
Memory-R1 is a cutting-edge approach that combines reinforcement learning techniques with the intrinsic memory functions of large language models. By utilizing reinforcement learning, these models can learn and adapt from interactions with their environment, much like humans do. This not only boosts their ability to recall information but also enables them to make smarter decisions based on past experiences.
The Role of Reinforcement Learning
Defining Reinforcement Learning
Reinforcement learning (RL) is a subset of machine learning wherein an agent learns to make decisions by taking actions in an environment to maximize some notion of cumulative reward. Unlike traditional supervised learning, where models learn from labeled data, RL agents learn through trial and error, refining their strategies to achieve better outcomes over time.
Enhancing Memory Through RL
In the context of LLMs, reinforcement learning is applied to strengthen the models’ memory management. By rewarding the LLMs for correctly recalling and applying past experiences, the models become more adept at retaining crucial knowledge. This leads to improved performance in tasks that require long-term memory and context retention, such as generating coherent text or engaging in meaningful conversations.
Key Advantages of Memory-R1
1. Improved Contextual Understanding
One of the most significant benefits of the Memory-R1 approach is its ability to enhance contextual understanding. Traditional LLMs may struggle to keep track of information over extended interactions. However, through reinforcement learning, Memory-R1 enables these models to remember critical context, ensuring that responses remain relevant and accurate, even in complex discussions.
2. Adaptive Learning
Memory-R1 allows LLMs to not only remember information but also to adapt it as new data becomes available. This adaptive learning capability ensures that models can update their knowledge base, leading to more dynamic and relevant outputs. As the model interacts with users over time, it becomes increasingly proficient at adjusting its memory based on ongoing feedback.
3. Increased Efficiency
With the enhanced memory capabilities afforded by Memory-R1, LLMs can operate with greater efficiency. The need to revisit and reprocess previously mentioned information is minimized, allowing for quicker response times and more fluid interactions. This efficiency is particularly valuable in applications like customer service and content creation, where timely responses are essential.
Applications of Memory-R1
The fusion of reinforcement learning with LLMs opens the door to numerous applications across industries:
1. Customer Support
In customer support, Memory-R1 enables AI-driven chatbots to provide more personalized and context-aware assistance. They can recall customer histories, preferences, and previous interactions, leading to more effective resolutions and increased customer satisfaction.
2. Content Creation
For content creators, Memory-R1 can significantly enhance productivity. It allows LLMs to remember themes, styles, and user feedback, enabling them to generate content that aligns closely with the creator’s objectives and audience expectations.
3. Education and Training
Educational platforms can leverage Memory-R1 to create adaptive learning experiences. By recalling students’ previous performances, the system can tailor lessons and resources to meet individual needs, fostering better learning outcomes.
Challenges and Considerations
While the Memory-R1 approach offers remarkable potential, it is not without challenges.
1. Complexity of Implementation
Integrating reinforcement learning into LLMs presents a unique set of complexities. Designing effective reward mechanisms requires a deep understanding of both the tasks at hand and the intricacies of human-like memory. This complexity can make development lengthy and resource-intensive.
2. Ethical Implications
As with any AI advancement, ethical considerations abound. There is a risk of reinforcing biases present in the training data, which could lead to perpetuating stereotypes or misinformation. Developers must take care to implement safeguards to mitigate these risks and promote fairness in AI responses.
The Future of Memory-R1 in AI
As research and development continue to progress, the future of Memory-R1 looks promising. Enhancements in computational power and algorithmic design will likely lead to even more robust memory capabilities, further bridging the gap between human-like reasoning and machine intelligence.
Conclusion
Memory-R1 represents a significant leap in how large language models manage memory through reinforcement learning. By improving contextual understanding, enabling adaptive learning, and increasing efficiency, this innovative approach opens new avenues for AI applications across various sectors. While challenges remain, the potential benefits of Memory-R1 can transform the landscape of AI and its interactions with humans, paving the way for a more intuitive and responsive future in technology.
As we advance toward a more AI-integrated world, embracing these developments will be crucial in harnessing the full capabilities of language models. The road ahead is filled with exciting possibilities, and Memory-R1 is at the forefront of this transformative journey.
