


Related posts

Fiverr Lays Off 30% of Workforce in AI-First Pivot
In the rapidly evolving landscape of technology, companies must adapt to stay competitive. A notable example of this is Fiverr, which h...

5 Strategic Steps to a Seamless AI Integration
Understanding AI Integration: A Guide for Success
Artificial Intelligence (AI) is reshaping industries, improving efficiencies, and enh...

Supercharge Headless WordPress Development with AI & Retrieval-Augmented Generation (RAG)
Supercharging Headless WordPress Development with AI and Retrieval-Augmented Generation (RAG)
In recent years, the landscape of web dev...
Hostinger Coupon Code 2025 – Hostinger Cloud Hosting, VPS Hosting, Web Hosting Discount Coupon Code
Unlock Amazing Savings with Hostinger Coupon Codes in 2025
In the ever-evolving digital landscape, finding reliable web hosting solutio...

Corporate Philanthropy Evolves: High-Impact Strategies for 2025
The Transformation of Corporate Philanthropy: Strategies for a High-Impact Future
As we dive into 2025, corporate philanthropy is witne...

Google AI Ships TimesFM-2.5: Smaller, Longer-Context Foundation Model That Now Leads GIFT-Eval (Zero-Shot Forecasting)
Introduction to TimesFM-2.5
In the fast-evolving landscape of artificial intelligence and machine learning, Google has taken a signific...
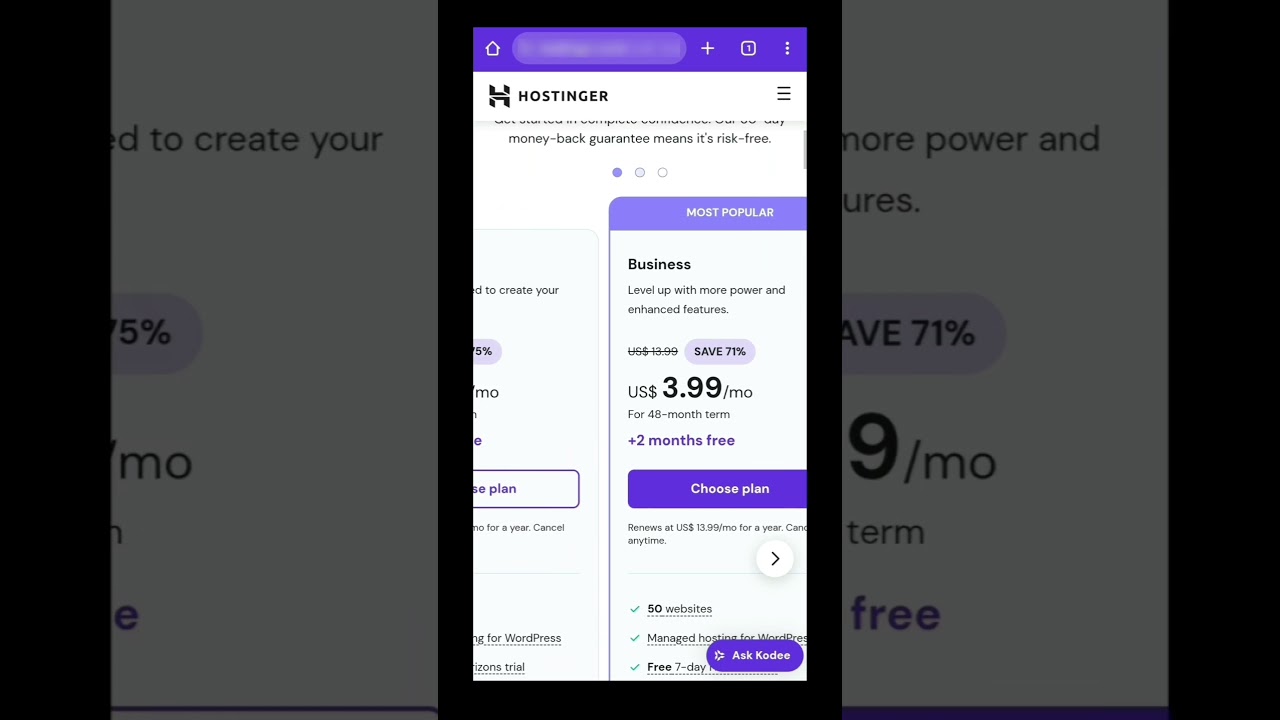
Hostinger Coupon Code 2025 – Hostinger Cloud Hosting, VPS Hosting, Web Hosting Discount Coupon Code
Discover Incredible Savings with Hostinger Coupon Code 2025
In the ever-evolving landscape of web hosting, choosing the right provider ...
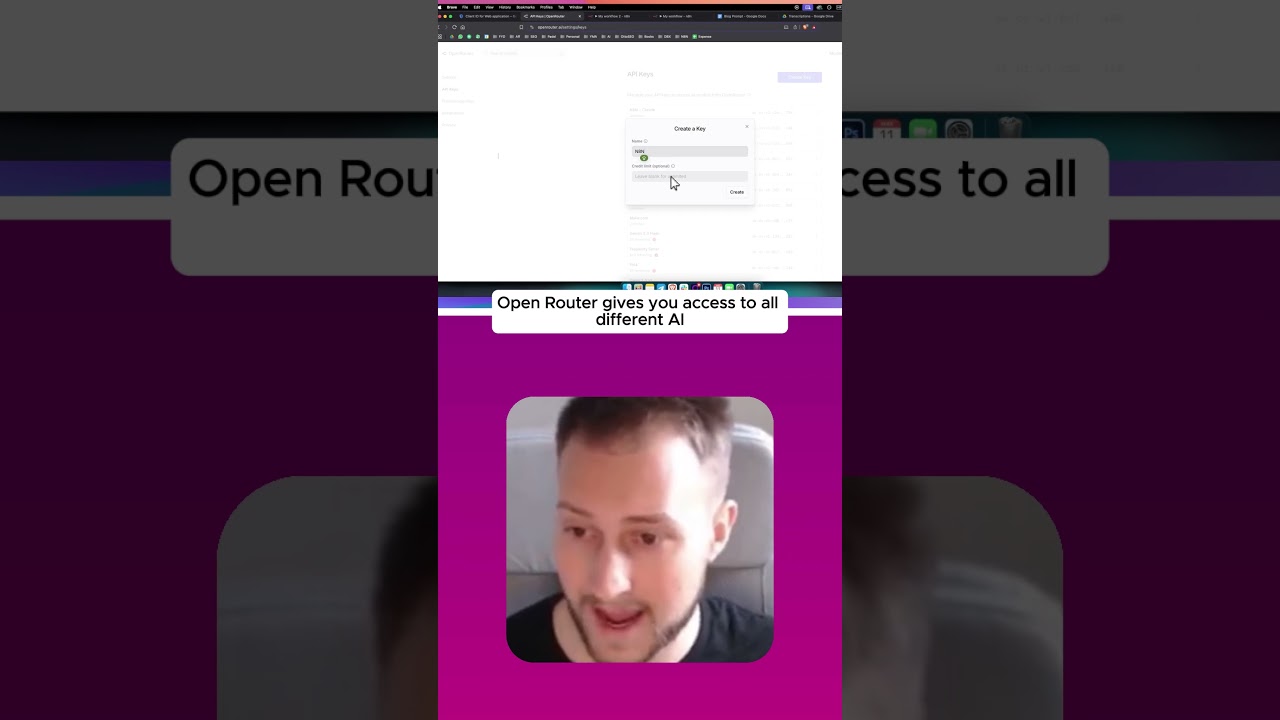
Adding A Chat Model to Automate Your WordPress Blog
Enhance Your WordPress Blog with Automated Chat Models
In today's digital landscape, customer engagement is more important than ever. F...

Hostinger Coupon Code 2025 – Hostinger Cloud Hosting, VPS Hosting, Web Hosting Discount Coupon Code
Unlock Incredible Savings with Hostinger Coupon Codes for 2025
In the ever-evolving world of web hosting, finding a reliable provider t...

Pulumi Launches Neo AI Agent for Natural Language Cloud Automation
Pulumi is paving the way for a revolutionary shift in cloud automation with the introduction of its Neo AI agent. This powerful tool ha...

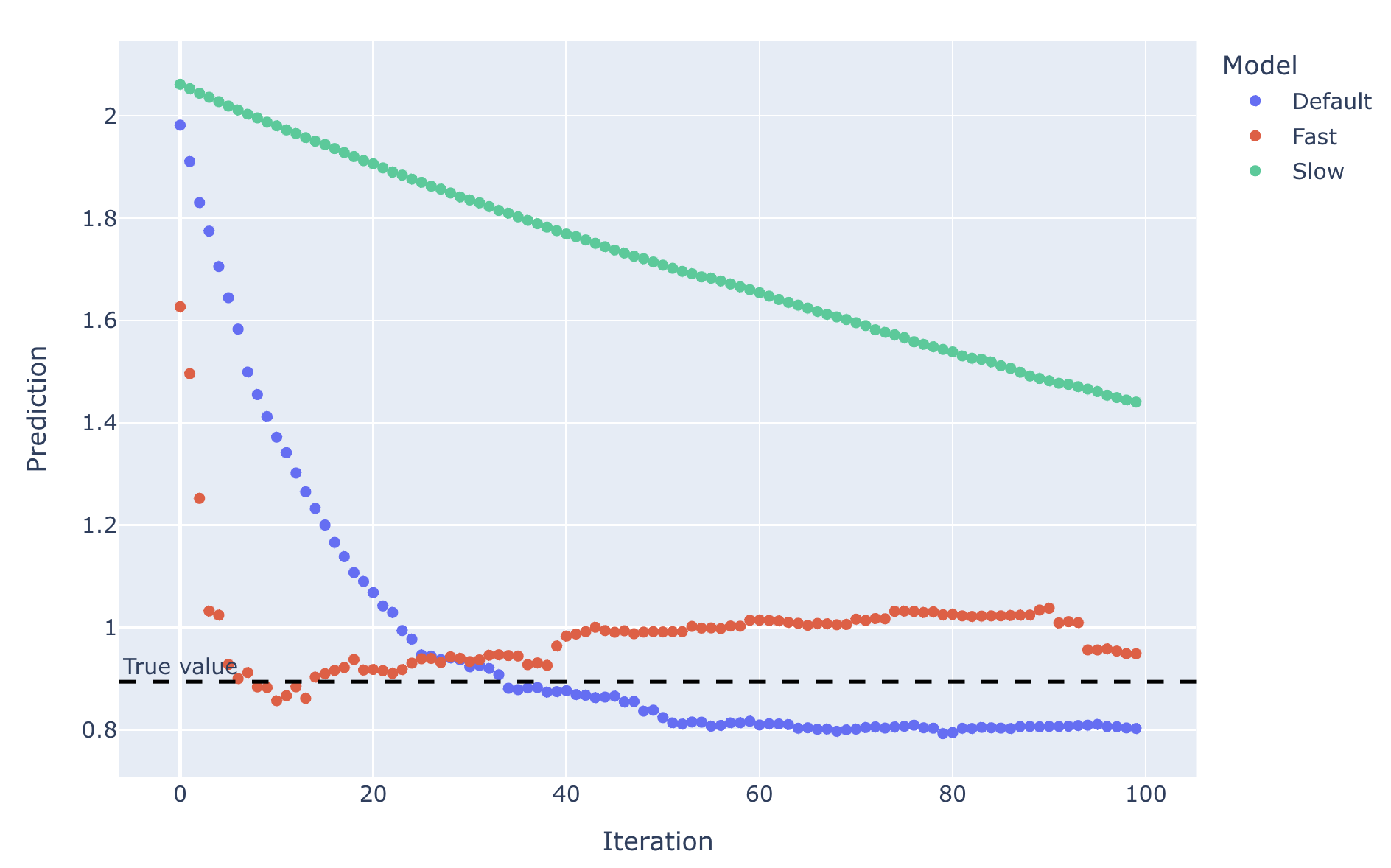
The Lazy Data Scientist’s Guide to Time Series Forecasting
Understanding Time Series Forecasting
Time series forecasting is a powerful technique that allows analysts to make predictions about fu...

Hostinger Coupon Code 2025 – Hostinger Cloud Hosting, VPS Hosting, Web Hosting Discount Coupon Code
Unlock Exciting Savings with Hostinger Coupon Codes for 2025
If you're in the market for reliable web hosting services, you're likely a...