
Blog
7 Drop-In Replacements to Instantly Speed Up Your Python Data Science Workflows
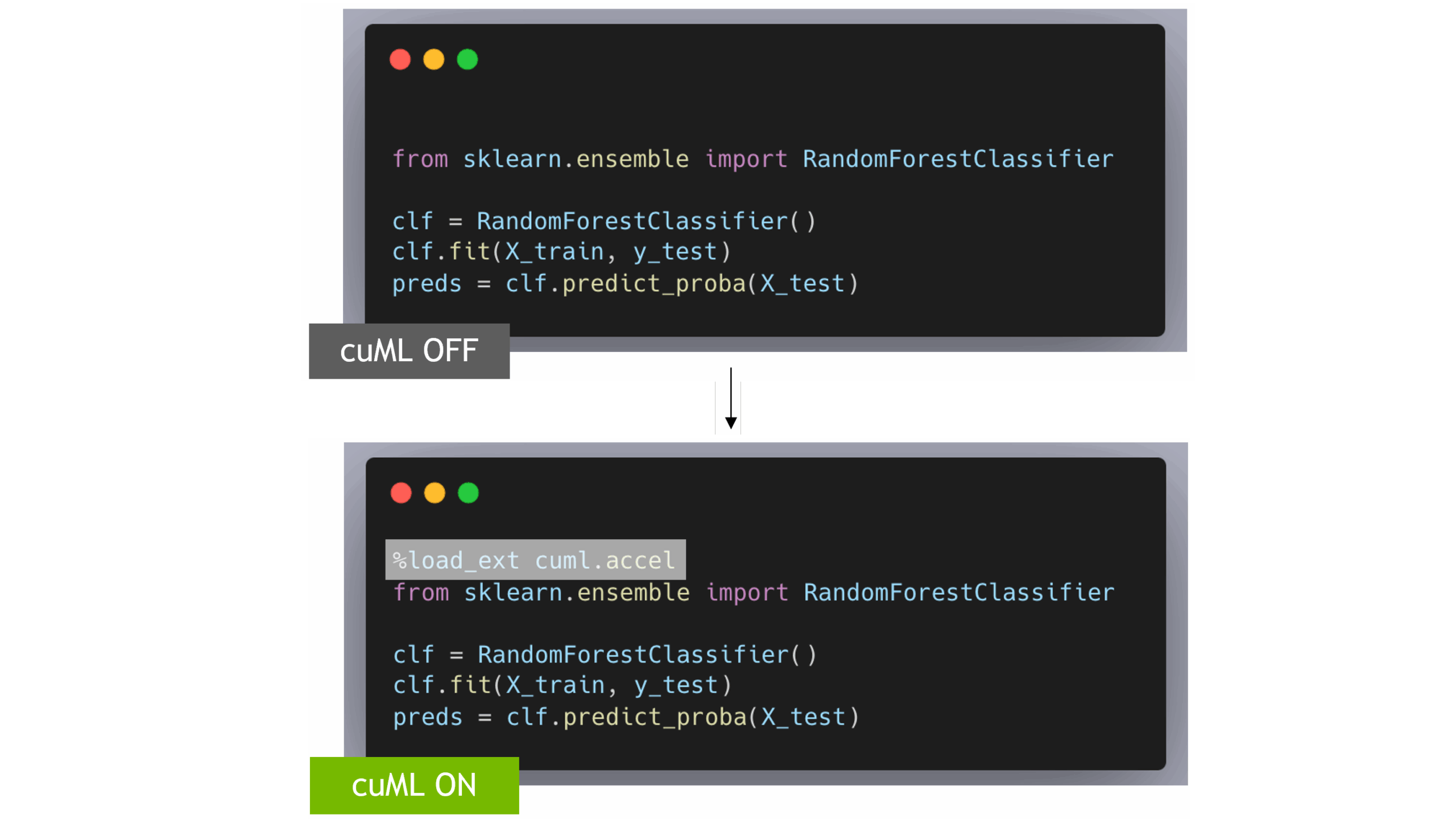
Boosting Your Python Data Science Workflows: 7 Essential Drop-In Replacements
Efficiency is paramount in data science, particularly when working with Python. Long processing times can hinder your productivity and delay project timelines. However, employing certain libraries and tools can dramatically enhance your workflows. Here are seven drop-in replacements that can elevate your Python data science strategies, making them more efficient and faster.
1. Numba: Accelerate Your Python Functions
If you are dealing with numerical functions in Python, Numba can be a game-changer. This Just-In-Time (JIT) compiler translates a subset of Python and NumPy code into fast machine code.
Key Features:
- Speed: Numba can optimize your functions to run orders of magnitude faster.
- Ease of Use: Simply decorate your functions with
@jit, and Numba does the rest. - Compatibility: Works seamlessly with NumPy arrays and functions, providing a familiar environment.
By incorporating Numba into your data science projects, you can significantly reduce execution times, allowing for quicker iterations and analyses.
2. Dask: Scale Your Data Tasks
When handling large datasets that don’t fit into memory, Dask emerges as a formidable tool. It extends NumPy and Pandas to work on larger-than-memory datasets using parallel computing.
Benefits of Dask:
- Parallel Execution: Dask coordinates tasks across multiple cores or machines, enhancing performance.
- Flexible Data Structures: Compatible with NumPy and Pandas, you can leverage familiar APIs while scaling up.
- Lazy Evaluation: It allows for efficient execution by only computing results when necessary.
Integrating Dask into your Python workflows can help eliminate memory constraints and streamline operations involving big data.
3. Vaex: Efficient Data Exploration
Data exploration can often be time-consuming, especially with large datasets. Vaex offers a compelling solution by enabling users to visualize and explore big data effortlessly.
Advantages of Using Vaex:
- Out-of-Core Computing: Handle datasets larger than memory without significant performance loss.
- Speedy Operations: Perform operations like filtering, groupby, and aggregations quickly and efficiently.
- Interactive Visualizations: Built-in capabilities for real-time visualization make exploratory analysis engaging.
With Vaex, data scientists can expedite exploratory work and gain insights faster.
4. Modin: Enhance Your Pandas Experience
For fans of Pandas who want to speed up their data processing tasks, Modin serves as an excellent alternative. It optimizes Pandas by distributing operations across multiple cores.
Why Choose Modin?
- Drop-In Replacement: Simply replace your Pandas import statement with Modin and retain familiar functionality.
- Parallelized Operations: Modin automatically distributes DataFrame operations, leading to quicker computations.
- Seamless Integration: Works with most existing Pandas code without modifications.
Switching to Modin allows data scientists to enjoy the robustness of Pandas while boosting performance.
5. PyArrow: Optimize Data Transfer
In data science, robust data transfer between different formats and systems can save time and enhance performance. PyArrow is a powerful tool designed for high-performance data interchange.
Features of PyArrow:
- Columnar Memory Format: This structure greatly enhances speed for analytical operations.
- Interoperability: Easily convert datasets between different formats (e.g., Parquet, Arrow, Feather) while maintaining performance.
- Integration with Pandas: PyArrow can seamlessly enhance Pandas operations for faster data manipulation.
Utilizing PyArrow can streamline your data ingestion and export processes, making them faster and more efficient.
6. TensorFlow Data API: Streamline Data Input for Machine Learning
When working on machine learning projects, efficiently inputting data into models is crucial. The TensorFlow Data API offers a robust pipeline to manage data efficiently.
Why Use TensorFlow Data API?
- Pipeline Creation: Create complex input pipelines for loading and preprocessing data on the fly.
- Performance Optimizations: Features like prefetching and parallel processing speed up the data loading phase.
- Integration: Works well with TensorFlow models, ensuring a smooth workflow.
Incorporating the TensorFlow Data API can simplify your machine learning projects by improving data handling speed.
7. Streamlit: Rapid Deployment for Data Apps
Finally, when transitioning from data analysis to data applications, Streamlit allows for rapid deployment of data models and visualizations.
Streamlit Highlights:
- Simplicity: Create web applications with minimal code; what takes hours becomes a matter of minutes.
- Interactive Features: Easily add sliders, buttons, and graphs, enhancing user engagement.
- Real-Time Update: The Streamlit app auto-updates as you change code, facilitating real-time feedback.
By using Streamlit, you can quickly transform your data analytics into interactive applications, enabling better insights and enhanced collaboration.
Conclusion: Elevating Your Data Science Productivity
Incorporating these seven drop-in replacements can significantly enhance your Python data science workflows. Whether you’re looking to speed up calculations, handle large datasets, or streamline data visuals, tools like Numba, Dask, Vaex, Modin, PyArrow, TensorFlow Data API, and Streamlit provide solutions for both speed and efficiency.
Adopting these libraries will not only save time but also allow you to focus on deriving insights and making data-driven decisions. By optimizing your workflows, you can increase productivity and innovation in your data science projects, enabling your team to achieve more with less effort.
